UPS Monitoring in Kubernetes: Graceful Shutdown with NUT + Prometheus
Every Kubernetes homelab guide covers networking, storage, and observability. Almost none cover what happens when the power goes out.
Without power management, a power failure kills all three nodes simultaneously. etcd commits get interrupted mid-write. Longhorn volumes lose both replicas at once. StatefulSet pods on dead nodes hang in Terminating indefinitely because the control plane can't confirm they're gone. Kubernetes even has a name for this: Non-Graceful Node Shutdown, a feature that exists specifically because abrupt power loss causes problems that the normal pod lifecycle can't handle.
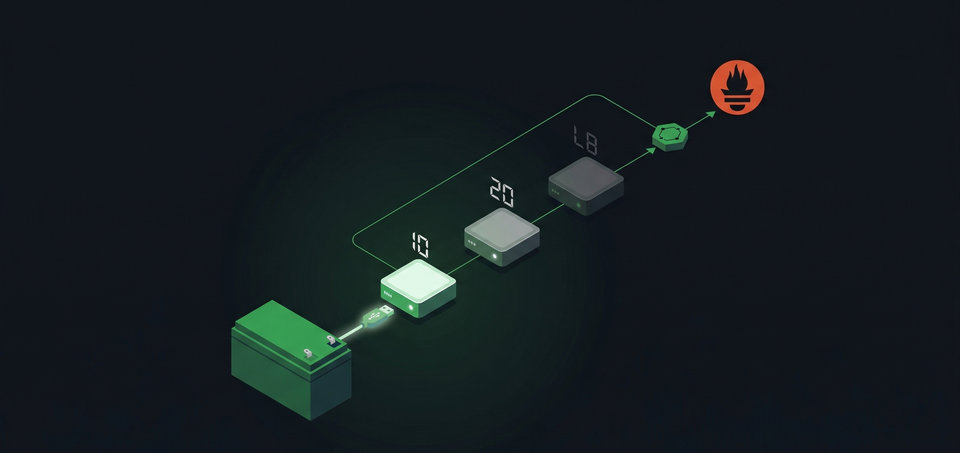
This cluster has a staggered shutdown pipeline that has never been triggered by a real power outage. Network UPS Tools (NUT) orchestrates node-by-node shutdown, kubelet drains pods cleanly, and 8 alert rules escalate across Discord and email. Whether it actually works under fire is an open question. This post covers the full architecture, the etcd quorum math that makes staggered shutdown necessary, and the gaps that haven't been closed yet.
What Happens When the Power Goes Out
From the moment the CyberPower CP1600EPFCLCD-NEMA UPS (1600VA / 1000W) switches to battery:
| Time | Event | Cluster State |
|---|---|---|
| 0:00 | Power fails, UPS switches to battery (OL→OB) | All 3 nodes healthy, etcd quorum 3/3 |
| 0:01 | Prometheus detects OB flag, UPSOnBattery fires | Discord #status notification |
| 0:05 | UPSBatteryWarning fires (charge < 50%) | Discord #status notification |
| 10:00 | cp3's upssched timer fires | cp3 begins graceful shutdown |
| 10:02 | cp3 finishes kubelet drain, powers off | etcd 2/3, quorum holds, pods reschedule to cp1/cp2 |
| 20:00 | cp2's upssched timer fires | cp2 begins graceful shutdown |
| 20:02 | cp2 finishes kubelet drain, powers off | etcd 1/3, quorum lost, cluster read-only |
| ~40:00+ | UPS firmware sets Low Battery flag | UPSLowBattery fires immediately (Discord #incidents + email) |
| ~40:00+ | cp1 upsmon detects LB, sends FSD to UPS | cp1 graceful shutdown, then UPS powers off |
The timing beyond 20 minutes depends on battery condition, ambient temperature, and actual load. The Low Battery flag is set by the UPS firmware based on its own runtime calculation, not a fixed timer.
The most important row in that table is 20:02. When cp2 powers off, the cluster drops to 1 of 3 etcd members. etcd cannot elect a leader with only one member (quorum requires 2). The API server can serve cached reads from its watch cache, but cannot commit new state. No pod scheduling, no lease renewals, no ConfigMap updates.
This read-only window is acceptable for two reasons. First, cp1 is the only node left and it's about to shut down too. Second, the graceful shutdown already happened on cp2 and cp3 while etcd had quorum. The pods that needed to reschedule already did.
If power returns during this window (after cp2 is down but before cp1 shuts down), the cluster won't fully recover until at least one other node boots and etcd reforms quorum. The etcd members aren't removed, just unreachable. When cp2 and cp3 restart, etcd automatically reforms without manual intervention. The graceful shutdown prevents the data corruption that would require a snapshot restore.
The rest of this post explains the four layers that make this sequence work.
The Pipeline
CyberPower UPS (battery + USB)
|
| USB HID
v
NUT Server (cp1)
|
| TCP 3493
+------------------+
| |
v v
NUT Client (cp2) NUT Client (cp3)
| |
| upssched | upssched
| (20 min timer) | (10 min timer)
v v
shutdown -h +0 shutdown -h +0
| |
| systemd | systemd
v v
kubelet graceful kubelet graceful
shutdown (120s) shutdown (120s)
NUT Server (cp1)
|
| TCP 3493
v
nut-exporter (K8s pod)
|
| /ups_metrics
v
Prometheus (scrape 30s)
|
+--------+--------+
| |
v v
Grafana (15 panels) Alertmanager
|
+------+------+
| |
v v
Discord Email
The UPS connects via USB to cp1 (10.10.30.11), the first control-plane node. At 11% load, roughly 110W for all three Lenovo M80q mini PCs, the UPS provides about 60 minutes of battery runtime. NUT 2.8.1 runs the server/client communication layer. A nut-exporter pod (v3.1.1) in the monitoring namespace bridges NUT into Prometheus.
NUT Architecture: Server, Client, Master
NUT uses a server/client model where one node owns the USB connection and the others connect over the network.
cp1 (server + master): The usbhid-ups driver communicates with the UPS over USB. The upsd daemon serves UPS data on port 3493. The upsmon daemon monitors UPS state and runs as master, which gives it one critical privilege: after all other nodes have shut down, the master sends the final power-off command to the UPS.
cp2 and cp3 (clients + slaves): Each node runs upsmon as a slave, polling the NUT server at 10.10.30.11:3493. Slaves shut down when instructed but never command the UPS to power off. If the master sent the power-off command first, the UPS would cut power while slaves were still running.
This creates a counterintuitive pattern: the master node shuts down last, not first. The node with the most authority over the UPS is the final one standing. It has to be. The master must wait until the UPS firmware sets the Low Battery flag, then send the Forced Shutdown (FSD) command, then shut itself down. Only after cp1 is off does the UPS cut power to the outlets.
Two NUT users exist: an admin with master privileges (used by cp1's upsmon) and a monitor with slave privileges (used by cp2, cp3, and the nut-exporter pod). Credentials live in Vault, pulled into Kubernetes via an ExternalSecret in the monitoring namespace.
Staggered Shutdown with upssched
When the UPS switches to battery, the simplest approach is to shut everything down immediately. The problem: that kills the cluster while you might only need a few minutes of runtime to ride out a brief outage. A 30-second power blip shouldn't trigger a full cluster teardown.
NUT's upssched solves this by introducing timers. Instead of shutting down on the first ONBATT event, each node waits a configured interval before pulling the trigger. If power returns, the timer cancels.
Only cp2 and cp3 use upssched. cp1 doesn't need it because cp1 (as the NUT master) relies on the UPS firmware's own Low Battery detection to decide when to shut down.
cp3 (first to go, 10 minutes):
# /etc/nut/upssched.conf on cp3
CMDSCRIPT /usr/local/bin/upssched-cmd
PIPEFN /run/nut/upssched.pipe
LOCKFN /run/nut/upssched.lock
AT ONBATT * START-TIMER early-shutdown 600
AT ONLINE * CANCEL-TIMER early-shutdown
AT LOWBATT * EXECUTE forced-shutdown
AT FSD * EXECUTE forced-shutdown
cp2 (second to go, 20 minutes):
The same config, but with START-TIMER early-shutdown 1200. Double the wait time.
The upssched-cmd script on both nodes handles the timer events:
#!/bin/bash
# /usr/local/bin/upssched-cmd
case $1 in
early-shutdown)
logger -t upssched "UPS on battery for timer duration, shutting down"
/sbin/shutdown -h +0
;;
forced-shutdown)
logger -t upssched "UPS forced shutdown, immediate power off"
/sbin/shutdown -h +0
;;
*)
logger -t upssched "Unrecognized command: $1"
;;
esac
The upsmon.conf on cp2 and cp3 routes notifications through upssched:
NOTIFYCMD /sbin/upssched
NOTIFYFLAG ONLINE SYSLOG+EXEC
NOTIFYFLAG ONBATT SYSLOG+EXEC
NOTIFYFLAG LOWBATT SYSLOG+EXEC
NOTIFYFLAG FSD SYSLOG+EXEC
Why stagger at all? At 11% load with 60 minutes of runtime, the numbers are conservative. But runtime isn't linear. As the battery drains, voltage drops and efficiency decreases. Shutting down cp3 at 10 minutes reduces load to roughly 7%, extending the remaining runtime by more than the 10 minutes spent. By the time cp2 shuts down at 20 minutes, cp1 is the only node drawing power, and the UPS has significant headroom before hitting low battery.
Kubelet Graceful Shutdown
When shutdown -h +0 fires on a node, systemd begins the shutdown sequence. Before kubelet, that meant containers got SIGKILL with no warning. Since Kubernetes v1.21 (beta), kubelet can intercept the shutdown signal using systemd inhibitor locks and delay the OS long enough to terminate pods cleanly.
All three nodes set shutdownGracePeriod: 120s and shutdownGracePeriodCriticalPods: 30s in /var/lib/kubelet/config.yaml. Both values must be non-zero to activate the feature. When a shutdown begins, kubelet marks the node NotReady (reason: "node is shutting down"), terminates regular pods with a 90-second window (120s minus 30s), then terminates critical pods (system-cluster-critical or system-node-critical priority class) with the remaining 30 seconds.
The detail that matters: the 120-second kubelet window is nested inside systemd's shutdown sequence, not additive to the NUT timer. When cp3's 10-minute upssched timer fires and runs shutdown -h +0, systemd starts stopping services. kubelet's inhibitor lock delays the final shutdown by up to 120 seconds while it drains pods. The total time from "upssched fires" to "node is off" is roughly 2 minutes, not 12.
This also means the upssched shutdown command must go through systemd, not bypass it. A raw poweroff -f or echo o > /proc/sysrq-trigger would skip the inhibitor lock entirely, and kubelet's graceful period would never run.
Monitoring the UPS
The live UPS state, as NUT sees it right now:
$ upsc cyberpower@localhost
battery.charge: 100
battery.runtime: 3600
battery.voltage: 13.5
battery.voltage.nominal: 24
device.model: CP1600EPFCLCD-NEMA
driver.name: usbhid-ups
input.voltage: 233.0
input.voltage.nominal: 230
output.voltage: 233.0
ups.beeper.status: disabled
ups.load: 11
ups.realpower.nominal: 1000
ups.status: OL
ups.timer.shutdown: -1
That's 1000W real power (not the 1600VA marketing number) at 11% load. Three mini PCs drawing 110W total, with 60 minutes of runway on a full charge.
A nut-exporter pod translates these NUT variables into Prometheus metrics. The interesting part of the Deployment is the variable selection:
args:
- --nut.server=10.10.30.11
- --nut.vars_enable=battery.charge,battery.voltage,
battery.voltage.nominal,battery.runtime,
input.voltage,input.voltage.nominal,
output.voltage,ups.load,ups.status,
ups.realpower.nominal,ups.beeper.status
Each NUT variable becomes a network_ups_tools_ prefixed metric. The ups.status field is special: NUT reports status as a composite string ("OL CHRG" for online and charging), and the exporter parses it into individual boolean metrics. network_ups_tools_ups_status{flag="OB"} == 1 checks a single flag without string parsing. The full metrics reference lists all 15 status flags the exporter tracks.
A ServiceMonitor scrapes the exporter every 30 seconds. Credentials come from Vault via ExternalSecret. A 15-panel Grafana dashboard (deployed as a ConfigMap) shows stat panels for current status, charge, load, and runtime, time-series graphs for historical trends, and a state-timeline panel that renders OL/OB/LB transitions as colored bands. The state-timeline is the most useful panel during a power event because it shows exactly when the UPS went to battery and for how long.
For alert routing, Part 7 covered the full UPS severity ladder. In summary: warning alerts (UPSOnBattery, UPSBatteryWarning, UPSHighLoad) go to Discord #status. Critical alerts (UPSLowBattery, UPSBatteryCritical, UPSExporterDown, UPSOffline) go to Discord #incidents and email. The Alertmanager inhibition rule suppresses UPSBatteryWarning when UPSBatteryCritical fires, so you get one notification per escalation step.
What's Missing
cp1's USB connection is a single point of failure. All three nodes depend on cp1's NUT server for UPS awareness. If the USB cable, port, or usbhid-ups driver fails, cp2 and cp3 lose their monitoring link. The NUT server logs show periodic "Data for UPS [cyberpower] is stale" warnings where the USB driver momentarily loses communication, resolving within 2 seconds each time. This is an observed behavior with USB HID UPS drivers under bus congestion. Not critical at current frequency, but if stale periods grow longer, the 15-second MAXAGE threshold could trigger false UPSExporterDown alerts.
The upssched-cmd scripts have no external notification. When a staggered shutdown actually triggers, the script logs to syslog and runs shutdown -h +0. No Discord notification, no webhook. The Prometheus alert chain (UPSOnBattery at 1 minute) covers the initial power loss, but there's no explicit "cp3 is shutting down due to UPS timer" message. Adding a curl to the Discord webhook before the shutdown command would close this gap.
Power management is the infrastructure layer that most homelab guides treat as optional. In a single-node setup, maybe it is. In a multi-node Kubernetes cluster with distributed etcd, distributed storage, and StatefulSets that don't handle surprise termination well, the difference between a graceful staggered shutdown and a simultaneous hard power-off is the difference between "the cluster recovered automatically" and "I spent Saturday morning restoring an etcd snapshot."